双路服务器谁为王 双Opteron激战双至强
-
前言:Opteron242和Xeon面对面
在我们前一次的测试里,大家已经领略了K8核心的桌面型处理器Athlon64(FX)的风采,它们的表现,给我们留下了深刻的印象。不过,对于一个处理器厂家来说,在中高端服务器、工作站市场站稳脚跟,显然是获取更多利润,打造品牌形象的上佳途径。AMD当然也清楚这一点,他们所推出的X86-64指令集及其执行者――Opteron就是为此而来。
近日,我们收到了强氧科技送测的双Opteron242平台和双Xeon平台整机各一套,在本文中,我们将和大家一起领略双处理器在专业图形工作站领域的双雄争霸战。
Opteron平台兵力配置分析
观看战局之前,还是让我们先来看看双方的兵力布置状况。
首先是AMD一方的处理器兵力状况:

处理器方面,AMD推出Opteron系列处理器,分为100、200和800三个系列,100系列只能在单处理器条件下运行,200系列则可支持双处理器,800系列可支持8处理器。
本次我们收到的样机则配备了两块1.6GHz的Opteron242处理器。在后面的硬件展示环节中将有详细的图片资料奉上。
芯片组方面,Opteron除了AMD自己的8000系列芯片组外,还获得了许多芯片组厂商的支援。
带宽的优势
除此之外,有关Opteron处理器,最引人注目的大概就是它区别于Intel Xeon的,异常灵活的内存接口形式了。
在Opteron系统中,与Xeon系统共享式内存结构所不同的一个特点是,各块Opteron处理器可以拥有自己的本地内存,他们共同组成一个节点(node)。各个节点内的处理器通过内置的内存控制器与节点内的内存交换数据。这样,在多处理器的情况下,系统的内存峰值带宽=节点数目×节点内部内存峰值带宽。如下图:

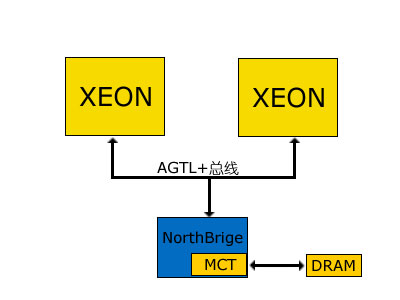
Opteron系统与Xeon系统共享式总线的对比
这样,对于一个2节点的Opteron242系统,假设每个节点内均使用DDR333内存组成双通道,那么整个系统的内存峰值带宽将为:2×(333×128/8)=2×5.3GB/s=10.6GB/s,随着节点数目的增多,带宽还将进一步增长。比起Xeon系统共享式内存结构内存带宽固定不变的情况,在多处理器的情况下存在较大的带宽优势。
以下,就是AMD自己使用SISoftsadra2003所测试的一组单Opteron、2×以及4×Opteron的内存带宽对比数据:

请注意上图中4Xeon系统测试得分与4Opteron846得分的悬殊对比,以及随处理器数目增多,Opteron系统分值的攀升状况。当然,由于该软件测试的是持续带宽,因此分值并不成2倍的比例增长。
两种不同的设计
不过,需要我们注意的是,虽然Opteron系统中各节点里的内存从物理上是从属于节点内部的。但与Xeon系统相同的是,系统中所有的Opteron处理器都可以通过连接各节点的Hypertransport总线访问到其它节点的内存。通过这种途径,可以做到所有的处理器共享系统全部的内存资源。既然如此,那么我们很自然地可以想到:每一个节点内部也不必都设置内存。
这样,就造成了Opteron体系中各个处理器访问本节点内存与访问其它内存时所需时间的不一致性;同时由于所有的内存为处理器所共享,就必须保证各个处理器中相关缓存的一致性。故此,人们把具备这种特性的多处理器系统形象地称为ccNUMA(Cache Coherence Non Uniform Memory Access)。
正是因为这种ccNUMA特性,就出现了两种不同的双Opteron主板设计。
第一种设计,是在每个节点内部都设置内存,这样的设计能够很好地发挥Opteron系统固有的带宽优势,充分利用了每一个处理器内部的内存控制器。上文中我们给出的结构图,以及AMD自己使用SISoftsadra2003所测试的内存带宽成绩,也是在这种设计的情况下得出的。
这种设计的代表有Tyan刚刚推出的Thunder K8W主板,如下图:

图为:完全发挥平台带宽威力的Thunder K8W主板
图中可见,4个内存插槽被分开布置到了两个CPU的附近,同时由处理器插槽引向内存插槽的数据线也清晰可见。
而另一种设计,则在某些节点内部不设置内存。这些节点内的处理器通过Hypertransport总线访问其它节点中的内存。如下图:
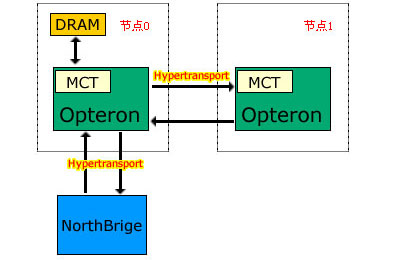
这种设计的代表有MSI微星科技的K8T Master―2 FAR(本次测试中,我们收到的样机就是使用这块主板):

图为:灵活设计的MSI K8T Master―2 FAR主板
图中可见,4个内存插槽是传统的排列形式,同时各个处理器到内存插槽的距离也差别较大,板上完全看不到2号处理器到内存插槽的数据连线。
这样做在内存存取延迟和内存带宽上会造成较大的性能损失,同时也使其中一个处理器的内存控制器不能发挥其应有的作用,从某种程度上说是一种不得已的设计。
但是纵观目前的主板市场,使用前一种方案设计的板子却是凤毛麟角,反而是后一种方案暂时大行其道。出现这种状况的原因是多方面的,一方面使用这种设计可以降低成本,并且,使用这种方案可以在单处理器版本主板的基础上稍作改进就可以推出双处理器版本,缩短了开发进度;另一方面更重要的因素是由于目前的Windows操作系统对于前一种设计的支持还不是很好,只有Windows2003 Server企业版以及仅发行了beta1版的WindowsXP64bit for AMD64才能对AMD64处理器提供ccNUMA特性的完美支持(当然在64位Linux平台上,这方面的支持是完备的)。在这种情况下,主板厂商们不得不退而求其次。
不过,瘦死的骆驼比马大,即便是使用第二种方案,K8大胆创新的内存体系仍然相比对手XEON具备一定的优势,这一点,在我们后面的测试中,将得到更好的体现。
Xeon平台兵力配置分析
而Intel这边,处理器方面,32位平台以Xeon以及Xeon MP两个系列对抗。前者只支持两个物理处理器,而后者可以在4―8个物理处理器的情况下使用。
与Opteron系列不同的是,在Intel Xeon(MP)阵营里,各款处理器缓存的容量存在一定的差异,这是需要大家特别注意的一个区别。在Xeon系列中,3.06G以下频率的就只带512KB二级缓存,同时3.06G的Xeon也被分为带1MB三级缓存的版本和不带1MB三级缓存的版本。当然,在64位平台上,还有安腾系列,但安腾平台并非本文的重点。目前为止,根据Intel官方所公布的最新数据,Xeon(MP)各款处理器的具体参数如下:
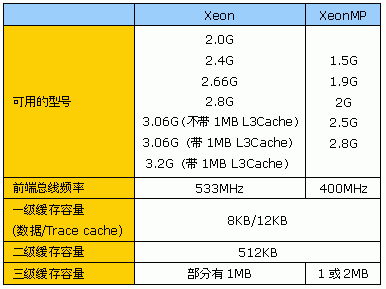
其余处理器参数与P4相比变化不大,在此就不重复列出了。
本次强氧科技送测的整机配备的是两块2.4GHz的Xeon处理器。
从Xeon以及XeonMP的数据来看,在Presccott核心对应的XEON推出之前,Intel目前主要是实行处理器频率提升与缓存容量增加两手抓的方针来应对Opteron的攻势,稍嫌消极。
芯片组方面,Intel在Xeon(MP)平台上目前主要依靠较新的E7505、E7501两个系列的芯片组,其中E7501从参数上看,主要由E7500增加支持的前端总线频率为533MHz而来,他们的结构图如下(由于同E7501类似,因此不重复贴出E7500的相关内容):


E7505、E7501系列芯片组结构图
图中可见,为了满足服务器、工作站市场的需求,除了通过Hub interface1.5接口连接传统的南桥之外,E7505、E7501、E7500均可通过数个Hub interface2.0接口连接82870P2 PCI―X功能扩展芯片实现对PCI-X的支持。它们的具体特性如下:

由特性表可见,与Opteron平台相比,除了缓存容量和处理器频率以及PCI-X功能扩展之外,Xeon平台的参数略显保守。而本次我们收到的强氧科技送测样机配备的,则为一块MSI基于E7505芯片的E7505 Master2-F。
参测双处理器系统介绍
下面,我们进入硬件实物的展示环节。本次测试,我们收到了来自强氧科技的两台双K8、双Xeon主机,下面是这两款整机的外观酷照:
首先是配备了双Opteron242、4条512MB ECC Registed DDR266内存,以及Quadro FX1000显卡的强氧整机登场亮相。

图为:双Opteron整机
随后是配备了双Xeon 2.4G处理器、4条512MB ECC Registed DDR266内存,以及Quadro FX1000显卡的强氧整机。

图为:双Xeon整机
两款主机分别采用双Opteron242以及双Xeon 2.4G处理器,下面是它们的对比图:

Opteron242和Xeon 2.4G对比
使用的主板,则分别是上文提及的MSI微星科技 K8T Master―2 FAR双Opteron主板,以及同为MSI产品的 E7505 Master2-F双Xeon主板。


图为:两个平台所使用的主板
两款整机的主板分别采用了K8T800+VT8237的南北桥组合以及E7505+ICH4的南北桥组合。不过配用双Xeon处理器的MSI E7505 Master2-F主板由于市场定位问题,因此并没有使用PCI-X扩展芯片。
测试配置介绍
好,以下,我们来介绍一下本次对比测试的详细配置,以及我们使用的测试软件情况:

非常遗憾的是,由于市面上的Registed DDR333/400内存非常稀少,而且送测的板子都不带内存频率调节功能,因此我们只能统一在DDR266条件下测试了。这样的内存参数对于E7505、E7501来说正好是标配,然而对于Opteron,则无法发挥其系统的全部效能了。
此外,考虑到图形工作站条件下,Win2000服务器版应用并不广泛,因此我们仅使用了Win2000专业版进行测试,这样,由于Win2000专业版仅支持最大2个逻辑/物理处理器,就不能在双Xeon平台上开启超线程功能了。
参数系统对比测试:SiSoft Sandra 2004
接下来我们进入实测环节。首先是使用SiSoft Sandra 2004进行两个平台的参数对比测试:
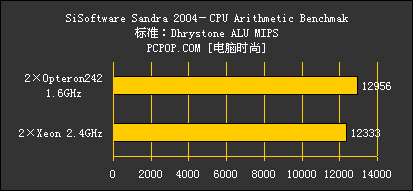


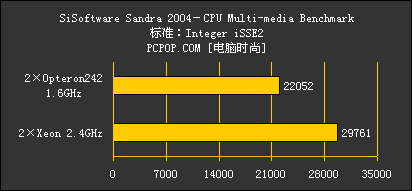

测试使用SiSoft Sandra 2004 v10.9.89版进行,详细测试结果如下:
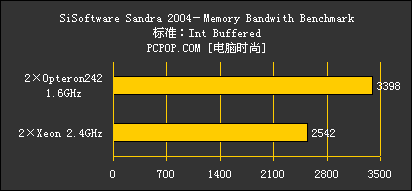
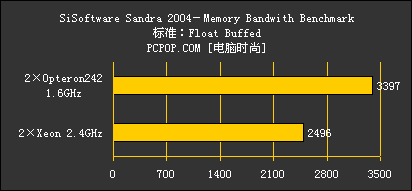
由于此次送测的Opteron频率偏低,仅1.6GHz,加上SSE2多媒体指令集执行的老问题,因此在前两大项测试中,即使没有打开Xeon上的超线程,Opteron242的分数在整数以及浮点矢量数据计算的情况下依然不及Xeon。
不过,在测试标量浮点数据的WhetstoneFPU MFLOPS测试中,Opteron242的优势却是十分明显的。看来,K8核心处理器优秀的标量浮点效能是Intel现有的Netbuser核心仅凭频率难以超越的。同时标量整数性能也小超Xeon,标量计算方面成绩不错。
而从内存带宽测试一项,我们可以看到,即便只使用一个处理器上的内存控制器,Opteron系统的内存带宽相比Xeon系统,仍然是占据比较明显的优势。
参数系统对比测试:ScienceMark 2.0
接下来,我们使用另一个常用的测试工具:ScienceMark 2.0来测试两个系统的内存子系统性能,以下是测试的详细结果:
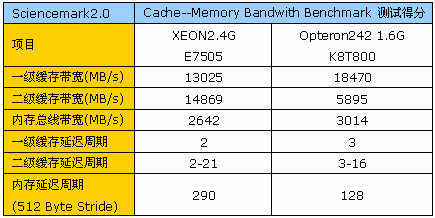
测试结果可见,尽管Opteron242一级缓存运行频率较低,但在带宽方面仍然胜过Xeon的一级缓存,领先程度达到40%左右,优势明显。
而到了二级缓存这边,情况则完全反过来,我们认为,Opteron二级缓存带宽性能的低下与其运行频率、接口位宽仅128bit为Xeon的一半不无关系。
最后,是内存带宽、延迟的较量,我们可以看到,即使使用的是妥协的方案,Opteron系统的相关参数仍然具备显著的领先优势。同时我们也必须注意到,使用妥协方案后,由于其中一个处理器需要经过Hypertransport总线访问内存,因此双Opteron内存延迟周期参数将有所下降,相比单处理器的情况,延迟增加6个总线周期左右。
参数系统对比测试:Linpack
Linpack测试是一种使用尺寸由小到大的浮点矩阵乘法计算来考核处理器标量浮点性能以及缓存、内存系统带宽、延迟性能的测试工具,主要用于分析缓存、内存系统性能。由于源码开放,因此受到许多测试的青睐。其支持多处理器的高级版本更是成为衡量超级计算机性能的权威工具。
我们使用的是Aceshardware的Linpack软件包进行测试,该软件包是征对Windows系统使用Linpack库文件重新编译的,由于只是一个简化的版本,因此不支持多处理器。但仍不失为一种为评价处理器性能提供参考的有力工具。以下为测试结果曲线图:

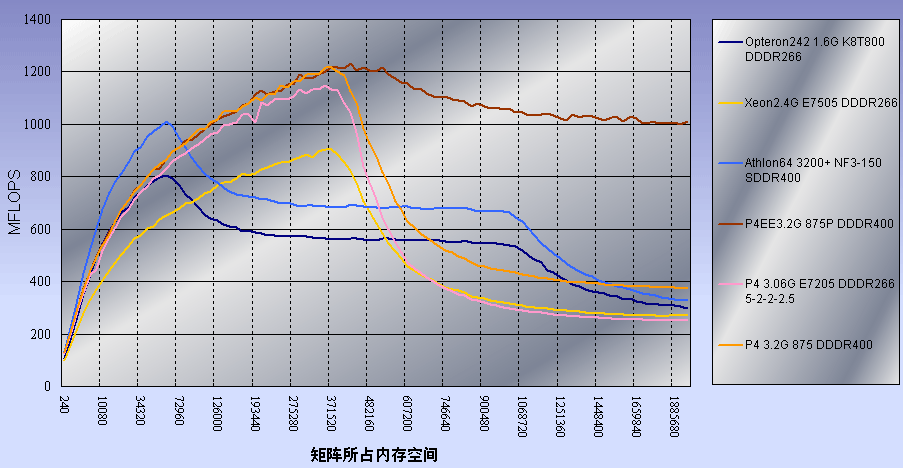
6款处理器的Linpack测试结果图(点击察看全图)
测试结果图中,纵坐标为测得的MFLOPS数(百万浮点计算次数/秒),而横坐标则为计算的矩阵尺寸大小。
为了让大家更好地理解Linpack软件测试,我们共使用了6款CPU进行测试。测试结果图中如无特别说明,则内存时序均为6-3-3-2.5。
由测试结果曲线我们可以看到:
◎ 在曲线的前段,由于此时矩阵尺寸较小,因此主要考核一级缓存的延迟和带宽性能;
◎ 而随着矩阵尺寸的增大,逐渐超过了K8的64KB一级数据缓存容量之后,处理器的MFLOPS出现第一次下降,这是由于此时计算所需要的数据已经无法被一级缓存所完全容纳,因此处理器必需到速度稍慢的二级缓存中读取,故此MFLOPS的成绩受到前端带宽不足的影响而开始下降;
◎ 最后,当矩阵尺寸进一步增大到超出二级缓存+一级缓存的容量(由于AMD处理器一直使用Exclusive的缓存结构,因此其缓存总容量应为二级缓存+一级缓存,对于Opteron,这个值是1064KB左右)时,处理器将不得不到速度更慢的内存中读取,因此出现第二轮MFLOPS的下降。这里由于Athlon64 3200+使用了DDR400内存,运行频率又较高,因此Linpack性能优于Opteron242。
而到了Intel P4以及Xeon这边,我们看到的,则是另一种形状的曲线。
◎ 相对于K8来说,在曲线图的前部,尽管运行频率较高,但由于一级缓存容量较小,因此其一级缓存效率似乎不及K8,即使是象P4EE 3.2G这样变态级的处理器,曲线前段也仅与1.6G的Opteron242持平;
◎ 但是到了体现二级缓存效率的曲线图中部这里,Intel的Netbuster体系则凭借频率、数据传输位宽较高,延迟较小的二级缓存获得了不小的优势。
◎ 不过,由于容量仅512KB,所以当矩阵尺寸超出其二级缓存容量的512KB左右时(由于Intel处理器一直使用共享式的缓存结构,因此其缓存总容量应为二级缓存或三级缓存的容量,对于2.4G的XEON,这个值是512KB左右),由于需要到内存中取数据,而P4、Xeon的内存子系统性能又不及K8,因此在曲线图的后部一路落后下去,同时由于在曲线图后部的前半段,Opteron可以从1064KB的总缓存容量中得益,因此领先幅度更大。
不过这里P4EE得益于2MB超大容量的L3 Cache,取得了惊人的成绩,MFLOPS数目一度高居1000以上!可以说是遥遥领先了。但应该注意到的是,由于这个Linkpack测试的最大矩阵所占内存容量仅1.9MB左右,没有超出P4EE的2MB L3 Cache容量,假使我们继续增大矩阵尺寸,P4EE曲线仍会迅速回落到P4体系应有的水平。
此外,由于P4 3.2GHz使用了双通道DDR400,因此在曲线图的后部领先也并不奇怪了。
同时,在曲线图中与Xeon 2.4G同为533MHz前端总线的P4 3.06G,虽然使用的内存时序参数高出Xeon2.4G不少,却仍在曲线后部落后Xeon,这应该是体现了各自的北桥芯片组内存管理效率上的不同了。
在Linpack测试中,考验标量浮点数据性能的前半段曲线特性,为K8浮点处理单元的高超性能提供了又一个有力的证据。
系统性能对比测试:3Dsmax 5.0 CPU最终渲染
接下来,我们进入实际性能测试的环节,考虑到此款系统主要面对的是图形工作站应用,因此我们的测试也以此为重点进行,首先是CPU最终渲染的相关测试:
我们先进行3Dsmax 5.0 的CPU最终渲染测试:

此项测试我们选用3Dsmax 5.0 自带的Apollo.ma、Island.ma以及Waterfall.ma三幅复杂程度由小到大的场景进行CPU最终渲染测试,以下是测试时的一些具体设置:
◎ 图片画质统一为35mm,1.316:1全尺寸电影级,分辨率为2048×1556像素,如下图:

◎ 打开了测试选项里的Enable SSE,如下图:

◎ 其余选项均保持安装后默认的状态,此外,我们安装了NVIDIA针对3Dsmax系列的
Maxtreme驱动,并对viewport进行了设置;
◎ 每幅画面的测试共进行3次,取最接近的2次结果计算平均值,得出系统的得分,每次测试前均重新启动系统。
以下为此项测试的详细结果数据:



在3Dsmax5.0的CPU最终渲染测试中,双处理器发挥了应有的威力,不过Opteron242的表现并没有我们想象中的那么好,反而落在了Xeon的后面,而且差距随着渲染复杂程度的增加而增大。想来是由于执行3Dmax5.0的SSE指令处理矢量数据时效果不佳,加上运行频率又比较低使然。
系统性能对比测试:CineBench 2003
接下来是CineBench 2003的测试。CineBench 2003基于MAXON公司的Cinema 4D,是为数不多的免费测试软件,由于测试支持SMP,还特别宣称对超线程提供了支持,因此同样受到不少测试的青睐。
测试中我们在显卡驱动中打开了Cinema 4D的优化选项,其具体的测试结果如下:
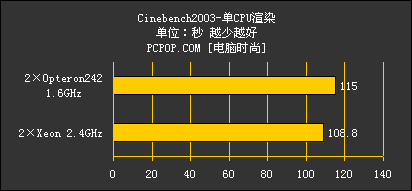




测试的结果是一面倒的局势,2.4GHz的双Xeon以2%~5%的优势在各项测试中领先1.6GHz的双Opteron242。不论是在考核最终渲染性能的单CPU、双CPU渲染测试,还是在考核预览性能的一系列测试中,Opteron242的表现都不令人满意。内存子系统性能和标量浮点性能的领先,并没在Cinebench2003中给低频Opteron带来切实的优势。
这里需要提醒大家注意的是,CineBench 2003的测试,虽然宣称支持SMP以及超线程技术。但是,只有在CPU渲染测试中能够从多处理器中得到性能提升,在其余的预览性能测试中,出现了使用双处理器的得分反而低于使用单处理器的情况。
系统性能对比测试:SPECviewperf 7.1.1
最后,是专业绘图软件的3D预览性能的测试,此项测试我们使用最近被SPEC组织认可的SPECviewperf 7.1.1进行。测试结果如下:




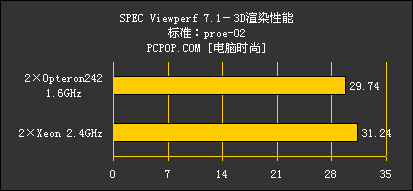

在SPECviewperf 7.1.1的测试中,双Opteron242平台也没有尝到任何甜头,在几乎所有的项目中都落后于双Xeon平台,仅在ugs-03一项中同Xeon成绩持平。当然,造成3D预览性能不佳的可能原因是多方面的,K8T800芯片组、驱动与Opteron242的较低频率都可能是造成这种结果的原因。
总结:革命尚未成功,同志仍需努力
从本次测试的结果来看,尽管在前面理论化的测试中Opteron在内存带宽、延迟以及标量浮点数据的测试中占据比较明显的优势,然而在后面的实际综合性能测试中,表现并不令人满意。我们认为,造成这些结果的原因,是多方面的,这其中很重要的因素有送测的Opteron242频率较低――仅1.6GHz,其次是SSE标量数据执行的问题;此外,操作系统、应用程序编译优化的问题也不容忽视。只有AMD圆满地解决了这些问题,才有可能使Opteron体系的威力充分发挥。当然,全面支持X86―64位指令以及Opteron体系ccNUMA特性的软件和操作系统能否逐步走向主流,也将是十分重要的因素。
行军的道路虽然布满荆棘,但AMD已经向Intel的桌面、工作站以及服务器阵地发起了新一轮强有力的全面攻击,我们也将为关心处理器市场的朋友们奉上最新战报和战事分析,与大家分享处理器战场前线的激烈战况!
PCPOP-电脑时尚 文/Cancerman
相关视频















相关阅读 Windows错误代码大全 Windows错误代码查询激活windows有什么用Mac QQ和Windows QQ聊天记录怎么合并 Mac QQ和Windows QQ聊天记录Windows 10自动更新怎么关闭 如何关闭Windows 10自动更新windows 10 rs4快速预览版17017下载错误问题Win10秋季创意者更新16291更新了什么 win10 16291更新内容windows10秋季创意者更新时间 windows10秋季创意者更新内容kb3150513补丁更新了什么 Windows 10补丁kb3150513是什么
- 文章评论
-
热门文章
 机甲mesuit好用吗 机甲
机甲mesuit好用吗 机甲 优酷路由宝怎么样 优酷
优酷路由宝怎么样 优酷 小米移动电源怎么样?
小米移动电源怎么样? 百度影棒怎么样?百度影
百度影棒怎么样?百度影
最新文章
 酷睿 i7-12700F处理器
酷睿 i7-12700F处理器 锐龙r5 3600和i5 1040
锐龙r5 3600和i5 1040
amd 5700显卡和2060对比 amd 5700xt和2070哪1660和1060哪个好 1660和1060性能差别对比黑加手环和小米手环3nfc哪个好 黑加手环和小apple pencil2代怎么样 apple pencil2代区别
人气排行 sata2和sata3接口区别评测小米AI音箱和小爱音箱mini版有什么区别 小爱挖矿用什么显卡比较好 2017挖矿显卡排名1660和1060哪个好 1660和1060性能差别对比a8和a9架构cpu的差别百度影棒怎么样?百度影棒一手评测赛钛客mmo7鼠标使用评测AMD Ryzen 7 1700x/1800x用什么主板?AMD R
查看所有0条评论>>